Popular Post
-
 I have got the comment on my previous post “ BIRT based Control Chart “ with questions about how actually in BIRT the data are prepared for ...
I have got the comment on my previous post “ BIRT based Control Chart “ with questions about how actually in BIRT the data are prepared for ... -
Your are welcome to post to this blog any message related to the Capacity, Performance and/or Availability of computer systems. Just put you...
Wednesday, December 9, 2015
Azure vs. AWS




 He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Tuesday, December 8, 2015
"The Challenge of Fairly Comparing Cloud Providers and What We're Doing About It" and "Benchmarking the Cloud" CMG'15 session
UPDATE: check the next post for this topic here:
Public Clouds Comparisons
This video presentation is very similar with CMG'15 presentation I have attended: "Benchmarking the Cloud" by Eric Hankland (Google, USA)
Abstract: The Google Cloud Performance team is responsible for the competitive analysis of Google Cloud products. This talk will cover the problems the team faces benchmarking Google Cloud Platform, some of the solutions we adopted, as well as two of our tools.
Public Clouds Comparisons
This video presentation is very similar with CMG'15 presentation I have attended: "Benchmarking the Cloud" by Eric Hankland (Google, USA)
Abstract: The Google Cloud Performance team is responsible for the competitive analysis of Google Cloud products. This talk will cover the problems the team faces benchmarking Google Cloud Platform, some of the solutions we adopted, as well as two of our tools.
Interesting that the CMG presentation also provided some interesting benchmaring for other public cloud providers including
- www.rackspace.com (price starts frpm 3 c/hour for LAMP stack instance)
- and some others
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Thursday, December 3, 2015
The Difference Between Microsoft Azure & Amazon AWS
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Wednesday, December 2, 2015
"#cloud service providers aren’t motivated to help businesses save money on their services"
"... cloud service providers aren’t motivated to help businesses save money on their services. If businesses using the cloud are reacting to problems, instead of proactively avoiding them through good planning, then they’re more likely to spend the extra money on last-minute solutions..."
 I have just ran into this very interesting point of view on the Capacity Planning for cloud based IT expressed by two major Capacity Management tools vendors (TeamQuest and Fluke Networks - I have used their tools in the past).
I have just ran into this very interesting point of view on the Capacity Planning for cloud based IT expressed by two major Capacity Management tools vendors (TeamQuest and Fluke Networks - I have used their tools in the past).
 He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Thursday, November 12, 2015
New Orleans Jazz Music in San Antonio at #CMG2015 final resection. # 4
I have really enjoyed the CMG'15 conference! I will do my best to make it even better next year!
See you all there!
| CMG'16 | La Jolla, CA | Nov 7th - 10th, 2016 |
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Thursday, November 5, 2015
#cmg2015 - Interviewing tips from Performance Dynamics
 He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
R. Jain talk at CMG - SDN, IoT, FCAPS, Fog computing, MCAD
http://www.cse.wustl.edu/~jain/talks/apf_cmg.htm
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Monday, November 2, 2015
"Linking Mainframe Monitoring, Anomaly Classification and Deep Analysis to Prevent Problem Reoccurrence" #CMG2015 - plan to attand
ABSTRACT:
"Mainframe monitoring does a great job of collecting and displaying system performance data. However in today's market monitoring is not enough - companies need accurate alerts, especially to handle issues arising from new mainframe usage paradigms driven by real-time end-user transaction systems and not just traditional backend transaction and batch processing. Also, many people with mainframe problem analysis skills are retiring making it harder to find people that can analyze mainframe monitor data for triage and problem resolution.This requires augmenting monitors with a "brain" " capable of accurate anomaly classification and alerts, and tying those alerts to deep dive activation - sense-and-respond can evolve into more a powerful mode of monitoring automation that we call predict-and-prevent. In this talk I'll discuss the capabilities needed by such a brain, which makes it possible to decide which anomalies are important and warrant a response, which need to be watched more closely to gather more information and which can be ignored.
"Mainframe monitoring does a great job of collecting and displaying system performance data. However in today's market monitoring is not enough - companies need accurate alerts, especially to handle issues arising from new mainframe usage paradigms driven by real-time end-user transaction systems and not just traditional backend transaction and batch processing. Also, many people with mainframe problem analysis skills are retiring making it harder to find people that can analyze mainframe monitor data for triage and problem resolution.This requires augmenting monitors with a "brain" " capable of accurate anomaly classification and alerts, and tying those alerts to deep dive activation - sense-and-respond can evolve into more a powerful mode of monitoring automation that we call predict-and-prevent. In this talk I'll discuss the capabilities needed by such a brain, which makes it possible to decide which anomalies are important and warrant a response, which need to be watched more closely to gather more information and which can be ignored.
Jacob P. Ukelson, D.Sc.
ConicIT
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Does your data have anomalies? #CMG2015
Check out @anoushnajarian's Tweet: about Neil Gunther workshope - https://twitter.com/anoushnajarian/status/661211860742615041?s=09

He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Thursday, October 29, 2015
IT Reincarnations: Outsourcing - Insourcing. Offshoring - Nearshoring. What's next? Clouding - ..... Condensing?
The End of IT?
"...autonomous self-healing and self-correcting systems ... are possible with predictive analytics and machine learning capabilites and the way infrastructure has become essentially code. It could spell the end of IT."
not so fast...
Surprise! The cost of cloud is about to rise!
So I have survived the 1st IT reincarnation (check my post "Возвращение в ИБМ")
Now I am involved in Clouding, which looks like Outsourcing 2.0, but this time instead of the personnel the IT infrastructure has been Outsourcing to Cloud provider. What would be the next cycle when the cost of clouds suddenly gets too high, just like the off-shore salaries had got high before In-sourcing?
"Condensing" back?
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Friday, October 2, 2015
How to Find a Rabbit in a Snowstorm: Outlier Detection at Netflix - repost
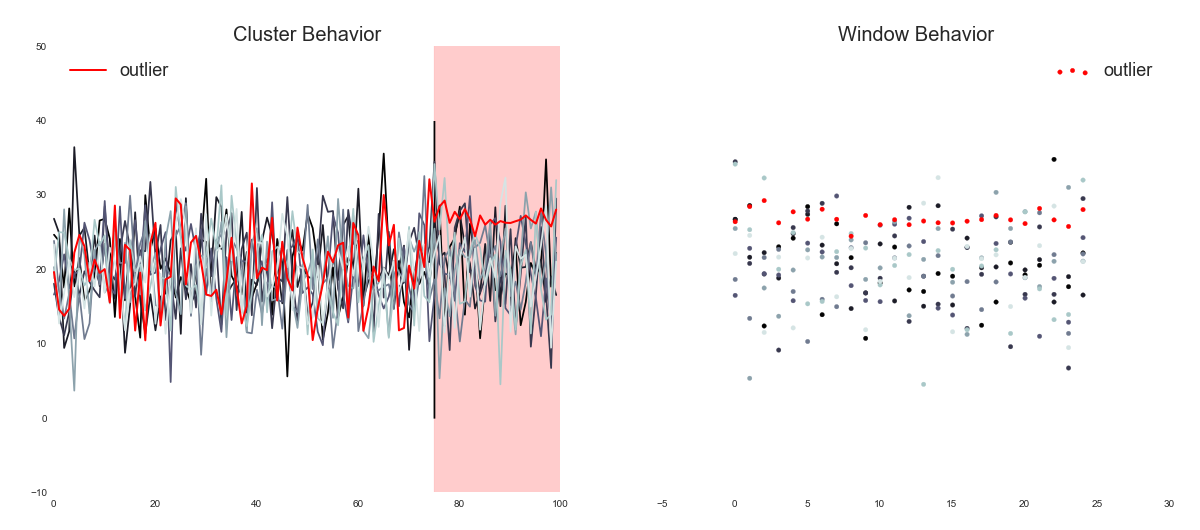 He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Monitoring Scape lists Anomaly Detection Tools

That a shame the SETDS is not there....
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Wednesday, August 26, 2015
The COMPUTER MEASUREMENT GROUP (www.CMG.org) membership has elected me to serve as Director for the 2016 - 2017 term
 He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Wednesday, July 22, 2015
SETDS is PADBI: Based on "Performance Anomaly Detection and Bottleneck Identification" ARTICLE in ACM COMPUTING SURVEYS · JUNE 2015
The ResearchGate site detected the citation to two SEDS papers from the survey article and brought the following survey to my attention.
Performance Anomaly Detection and Bottleneck Identification
Olumuyiwa Ibidunmoye, Francisco Hern´andez-Rodriguez, Erik Elmroth
Umea University, Sweden. July 3, 2015
Abstract
In order to meet stringent performance requirements, system administrators must
eectively detect undesirable performance behaviours, identify potential root causes
and take adequate corrective measures. The problem of uncovering and understanding
performance anomalies and their causes (bottlenecks) in di↵erent system and application
domains is well studied. In order to assess progress, research trends and identify
open challenges, we have reviewed major contributions in the area and present our
findings in this survey. Our approach provides an overview of anomaly detection and
bottleneck identification research as it relates to the performance of computing systems.
By identifying fundamental elements of the problem, we are able to categorize existing
solutions based on multiple factors such as the detection goals, nature of applications
and systems, system observability, and detection methods.
Reading this (published also in ResearchGate site) I got impression that is a very good overview of "PADBI" systems where SEDS has its place among other SPC/MASF ones. By the way the paper gives a short definition of MASF referencing the Busen and Bereznay work:
"According to Bereznay ... [100], SPC is not suitable for interval based sampling data
such as system performance traces. This motivates the development of the Multivariate
Adaptive Statistical Filtering (MASF) method. MASF, [101] is a SPC framework for detecting
changes in a Gaussian distribution."
SEDS (2 references to SEDS CMG papsers) has got its places under SPC section in this survey:

Performance Anomaly Detection and Bottleneck Identification
Olumuyiwa Ibidunmoye, Francisco Hern´andez-Rodriguez, Erik Elmroth
Umea University, Sweden. July 3, 2015
Abstract
In order to meet stringent performance requirements, system administrators must
eectively detect undesirable performance behaviours, identify potential root causes
and take adequate corrective measures. The problem of uncovering and understanding
performance anomalies and their causes (bottlenecks) in di↵erent system and application
domains is well studied. In order to assess progress, research trends and identify
open challenges, we have reviewed major contributions in the area and present our
findings in this survey. Our approach provides an overview of anomaly detection and
bottleneck identification research as it relates to the performance of computing systems.
By identifying fundamental elements of the problem, we are able to categorize existing
solutions based on multiple factors such as the detection goals, nature of applications
and systems, system observability, and detection methods.
Reading this (published also in ResearchGate site) I got impression that is a very good overview of "PADBI" systems where SEDS has its place among other SPC/MASF ones. By the way the paper gives a short definition of MASF referencing the Busen and Bereznay work:
"According to Bereznay ... [100], SPC is not suitable for interval based sampling data
such as system performance traces. This motivates the development of the Multivariate
Adaptive Statistical Filtering (MASF) method. MASF, [101] is a SPC framework for detecting
changes in a Gaussian distribution."
SEDS (2 references to SEDS CMG papsers) has got its places under SPC section in this survey:

Where:
[100] Frank M Bereznay and Kaiser Permanente. Did something change? using statistical
techniques to interpret service and resource metrics. In Int. CMG Conference, pages
229–242, 2006.
[101] Jerey P Buzen and Annie W Shum. Masf-multivariate adaptive statistical filtering.
In Int. CMG Conference, pages 1–10, 1995.
[105] Igor A Trubin and Linwood Merritt. ” mainframe global and workload level statistical
exception detection system, based on masf”. In Int. CMG Conference, pages 671–678,
2004.
[106] Igor Trubin et al. Capturing workload pathology by statistical exception detection
system. In Proceedings of the Computer Measurement Group. Citeseer, 2005.
Nice to see our CMG folks mentioned in the review! In general, that is a most complete high level overview of all types of SETDS-like systems and methods I have ever read. And there are a lot of them mentioned in the article!
But a few things could be missed there, for instance the idea of using the EV - Exception Value - to range the anomalies and to use that for detecting phases in the historical sample by analyzing this EV meta-metric. That is actually a way to cluster sample data in order to use it then for better prediction or correlation. See more details about EV here: The Exception Value Concept to Measure Magnitude of Systems Behavior Anomalies.
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Friday, June 19, 2015
Papers with citations to my work: 1. "Automated detection of performance regressions using statistical process control techniques"
Abstract
The goal of performance regression testing is to check for performance regressions in a new version of a software system. Performance regression testing is an important phase in the software development process. Performance regression testing is very time consuming yet there is usually little time assigned for it. A typical test run would output thousands of performance counters. Testers usually have to manually inspect these counters to identify performance regressions. In this paper, we propose an approach to analyze performance counters across test runs using a statistical process control technique called control charts. We evaluate our approach using historical data of a large software team as well as an open-source software project. The results show that our approach can accurately identify performance regressions in both software systems. Feedback from practitioners is very promising due to the simplicity and ease of explanation of the results.
6 AUTHORS, INCLUDING:
Thanh H. D. Nguyen
Queen's University
14 PUBLICATIONS 246 CITATIONS
SEE PROFILE
Bram Adams
Polytechnique Montréal
100 PUBLICATIONS 686 CITATIONS
SEE PROFILE
Ahmed E. Hassan
Queen's University
196 PUBLICATIONS 2,454 CITATIONS
Trubin et al. [18] proposed the use of control charts for infield
monitoring of software systems where performance counters
fluctuate according to the input load. Control charts can
automatically learn if the deviation is out of a control limit,
at which time, the operator can be alerted. The use of control
charts for monitoring inspires us to explore them for
the study of performance counters in performance regression
tests. A control chart from the counters of previous
test runs, may be able to detect “out of control” behaviours,
i.e., deviations, in the new test run.
...
[18] I. Trubin. Capturing workload pathology by statistical
exception detection system. In Computer
Measurement Group (CMG), 2005
_______
The next paper that has citations to my work is in the next post:
SETDS is PADBI Based on "Performance Anomaly Detection and Bottleneck Identification" ARTICLE in ACM COMPUTING SURVEYS · JUNE 2015
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
My Statistics at the ResearchGate: 238 publication downloads, 618 views, 13 citations
I see the interest to my publications is growing:

Publication downloads

So you also may want to look at my 15 publications at https://www.researchgate.net/profile/Igor_Trubin and you are welcome!
Check my next posts with papers that have citation to my work:
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Saturday, June 13, 2015
Anomaly detection by using R
8/2017 UPDATE: My ML based anomales and patterns change detection tool - SETDS was redeveloped on R. See more details:
_______________________________________ original post:
I have already suggested (and partially tested) to use R to developed an exception (anomaly) detector by applying my SETDS Methodology. You can find some simple examples in my CMG.org papers or here or at the following post:
I did not used any specific statistical packages for that
(e.g. qcc), but I see now some very specific ones have been appearing that could be used to detect different type of anomalies.
Here is one at Twitter Blogs:
Introducing practical and robust anomaly detection in a time series
Not sure how the approach evaluate (score) significance of the anomaly like EV meta-metric does in my SETDS Methodology. I see at least it puts them in some categories such as "global anomalies" and "local anomalies".
 I may want to test the package. You?
I may want to test the package. You?
Igor = I go R. I have redeveloped SETDS on R = SonR
I have already suggested (and partially tested) to use R to developed an exception (anomaly) detector by applying my SETDS Methodology. You can find some simple examples in my CMG.org papers or here or at the following post:
SEDS-Lite: Using Open Source Tools (R, BIRT, MySQL) to Report and Analyze Performance Data
I did not used any specific statistical packages for that
(e.g. qcc), but I see now some very specific ones have been appearing that could be used to detect different type of anomalies.
Here is one at Twitter Blogs:
Introducing practical and robust anomaly detection in a time series
Not sure how the approach evaluate (score) significance of the anomaly like EV meta-metric does in my SETDS Methodology. I see at least it puts them in some categories such as "global anomalies" and "local anomalies".
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Friday, June 5, 2015
Meeting Capital One

 He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Tuesday, June 2, 2015
St.Petersburg State Polytechnical University where I spent 25 years of my live studying and working is now the 14th best University in Russia.
 He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Thursday, April 9, 2015
I am going to SCMG Meeting Richmond on Friday April 24, 2015. You?
Southern Computer Measurement Group
SCMG Meeting Richmond
April 24, 2015
Location:
|
Agenda:
| Time | Session | Presenter |
8:00-9:00
| Registration, Continental Breakfast and Sponsor (MVS Solutions) Presentation | |
9:15-10:15
| Automated Capacity Management |
John Baker
|
10:30-11:30
| Memory Caches | Claire Cates |
11:30-12:30
| Lunch and Sponsor Presentation | |
12:30-1:30
| z/OS Performance "HOT" Topics |
Kathy Walsh
|
1:45-3:15
| The Target Breach and Beyond: Security Challenges in the 21st Century | Phil Smith |
3:30-4:00
| Wrapup | Linwood Merritt |
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Wednesday, March 18, 2015
My 1st job was IBM/370 system engineer, so I respect IBM mainframe a lot. And it turned 50!
The mainframe turns 50, or, why the IBM System/360 launch was the dawn of enterprise IT

BTW See my last post about me implementing Exception based Capacity Management for Mainframe here: Z Capacity Management without SAS and MXG

BTW See my last post about me implementing Exception based Capacity Management for Mainframe here: Z Capacity Management without SAS and MXG
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Monday, March 9, 2015
The Netflix Tech Blog: RAD - Outlier Detection on Big Data
The Netflix Tech Blog: RAD - Outlier Detection on Big Data:
Outlier detection can be a pain point for all data driven companies, especially as data volumes grow. At Netflix we have multiple datasets growing by 10B+ record/day and so there’s a need for automated anomaly detection tools ensuring data quality and identifying suspicious anomalies. Today we are open-sourcing our outlier detection function, called Robust Anomaly Detection (RAD)...
Outlier detection can be a pain point for all data driven companies, especially as data volumes grow. At Netflix we have multiple datasets growing by 10B+ record/day and so there’s a need for automated anomaly detection tools ensuring data quality and identifying suspicious anomalies. Today we are open-sourcing our outlier detection function, called Robust Anomaly Detection (RAD)...
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Friday, February 13, 2015
My top skills based on my 316 LinkedIn connections are: Capacity Planning (57), Databases (47), Performance tuning (42), BI (34) and Capacity Management (31).
 He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Thursday, January 29, 2015
Now you can support my blogging activity.
Now you can support my blogs. Every contribution is helpful, big or small! Please click "Support" on the frontage of my channel HERE!

He started in 1979 as IBM/370 system engineer. In 1986 he got his PhD. in Robotics at St. Petersburg Technical University (Russia) and then worked as a professor teaching CAD/CAM, Robotics for 12 years. He published 30+ papers and made several presentations for conferences related to the Robotics and Artificial Intelligent fields. In 1999 he moved to the US, worked at Capital One bank as a Capacity Planner. His first CMG.org paper was written and presented in 2001. The next one, "Exception Detection System Based on MASF Technique," won a Best Paper award at CMG'02 and was presented at UKCMG'03 in Oxford, England. He made other tech. presentations at IBM z/Series Expo, SPEC.org, Southern and Central Europe CMG and ran several workshops covering his original method of Anomaly and Change Point Detection (Perfomalist.com). Author of “Performance Anomaly Detection” class (at CMG.com). Worked 2 years as the Capacity team lead for IBM, worked for SunTrust Bank for 3 years and then at IBM for 3 years as Sr. IT Architect. Now he works for Capital One bank as IT Manager at the Cloud Engineering and since 2015 he is a member of CMG.org Board of Directors. Runs UT channel iTrubin
Subscribe to:
Posts (Atom)